Exploration of Collaborative Editing Technology
Collaborative editing has always been a missing feature of our PingCode Wiki because of the difficulty in technical implementation. However, the collaborative editing technology itself has been developed for many years, and the solution is relatively mature. Our team has just completed the implementation of the collaborative editing program based on the PingCode Wiki editor in Q3, so here I would like to talk about my opinions based on our technical selection and practical experience. Understanding of collaborative editing.
The main content is based on collaborative editing technology, and the understanding of technological development and evolution will also be discussed in the middle.
A scene
A common scenario, page publishing conflicts, this interaction has really existed in our products
Two users made changes based on the same article content. One user posted first, and the latter user would have such a reminder when posting. Although there were prompts, it was very unfriendly to users.
There are usually three product solutions:
- Pessimistic lock (a document can only be edited by one user at the same time)
- Contents are automatically merged and conflicts handled (this is what Gitbook products do)
- Real-time collaborative editing
Gitbook interaction:
Gitbook is also a way to solve problems, and then look at the interaction of real-time collaborative editing:
The mainstream collaborative editing interaction is like this. You can see the list of collaborators and where each collaborator is typing, and see what they are typing in real time. We can even talk to each other directly, which can effectively avoid conflicts.
Although collaborative editing is finally presented to users with this interface, there are complicated technologies behind it. Let’s take a look at how collaborative editing works.
Meet real-time collaborative editing
Guiding ideas:
The system doesn’t need to be right, it just has to be consistent, and it needs to try to keep your intent.
I think this sentence can be used as a guiding idea for the conflict handling of collaborative editing. It explains one thing very concisely and clearly, that is, the conflict handling of collaborative editing is not necessarily completely correct, because conflicts originally mean that the operations are mutually exclusive. , The operating intentions of the mutually exclusive parties cannot be completely retained. The most important thing for conflict handling is to ensure the consistency of the final data of both parties, and then strive to maintain their respective operational intentions on this basis.
Talk about the rich text data model
Collaborative editing is a technology built on the rich text editor. Its implementation depends on the design of the rich text data model. Here are two more representative data models:
2012 Quill -> Delta
2016 Slate -> JSON
Delta
Quill editor displays a paragraph of text
Its data representation is like this
It defines three operations (insert, retain, delete). Each operation record generated by the editor saves the corresponding operation data, and then uses a series of operations to express the rich text content, and the operation list is the final result.
Slate’s data model (JSON)
There is a picture type data in the editor, centered display
Corresponding data structure
Set the picture right operation
We can see that although the representation of Delta and Slate data is different, they have one thing in common, that is, the modification of the data can be expressed by the operation object. This operation object can be transmitted in the network to realize the content update based on the operation. This is a basis for collaborative editing.
In the following part, I want to talk about the core problems faced when implementing collaborative editing.
Problems of collaborative editing
Here is the first to throw out the problem, let everyone understand the problem scene faced by the collaborative editing, start from the problem, and then discuss the solution.
Problem 1: Dirty path problem
If there are three paragraphs in the editor, as shown below
Here is a simple simulation of the three paragraphs above with an array. The following figure shows a process of two users concurrently modifying data
The top is the original data structure. The left and right sides represent the operation sequence of the two users, and their states are the same at the beginning.
The user on the left inserts a new paragraph “Access” at Index=2, and the user on the right inserts a new paragraph “Testhub” at Index=4. First, they apply their own operations, and then pass their own operations to the message service On the other hand, at this time, the user on the left receives the synchronized message “Insert Texthub at Index=4” from the user on the right and applies the result on the left. This result is problematic and inconsistent with the final result on the right.
The reason is that the first insert operation performed by the user on the left has caused the index of the data behind it to change. Then the exception of the above figure will occur when the synchronized operation is directly applied. I call this situation a dirty path problem.
Problem 2: Concurrency conflict problem
Here is an example of the image data structure introduced above to illustrate the problem of concurrency conflict. The following figure shows the process of the problem. In order to easily understand the image node, only the two fields of type and align are reserved.
The top data structure shows that the two users are based on the same state at the beginning, and the picture is displayed in the center.
The user on the left changes the center status to the left, and the user on the right changes the center status to the right. According to the default processing, they pass their operations to the other party through the message service, which will cause the left to finally display the right and the right to finally display the left, and the data will be inconsistent. ,This situation is called concurrency conflict, they modify the same attributes based on the same location.
Problem 3: undos/redos problem
The essence of the undos/redos problem is still the aforementioned “dirty path problem” + “concurrency conflict problem”, but the scenarios in which the problem occurs are somewhat different and complicated, so I propose it separately here.
It is still the data operation of the previous “dirty path problem”. Here, only look at the right part and analyze its undo stack:
User’s operation list on the right:
User undo stack on the right (the undo sequence is opposite to the operation sequence):
① Delete the node at Index=2
② Delete the node at Index=4
The execution of this undo logic is actually problematic. The reason is that the trigger (Origin) of the operation corresponding to the undo operation ① is the user on the left. If the user on the left is executed according to this undo logic, the user on the left may be blinded: “What I just entered It’s gone!” Although it can be explained logically, it does not conform to the user’s usage habits, so for collaborative editing scenarios: undo operations should only undo their own operations, and the coordinator’s operations should be ignored.
After modifying the undo stack of the user on the right:
① Delete the node at Index=4
You can see that the undo stack only contains the operations on the right, but this brings another problem. If you look carefully, you can find that the node corresponding to Index=4 is “Plan”. At this time, the withdrawal will delete the “Plan”. The actual node inserted by the user on the right is “Testhub”, and there is a dirty path again.
In addition to this “dirty path” problem, the “concurrency conflict” problem will also appear in undso/redos in a similar way, and the specific logic will not be analyzed in detail.
After the undo stack ignores the operation of the collaborator, the operation path in the undo stack will have a “dirty path” problem + a “concurrency conflict” problem
Question 4: Project landing problem
This question is easier to understand, which is the specific landing problem of collaborative editing:
- Synchronization of operations
- Cursor synchronization
- Network agnostic (network jitter, network delay, etc.)
- Document version history
- Offline editing
- …
Summarizing the problems mentioned above, they can actually be divided into two categories:
The first category:
mainly includes dirty paths, concurrency conflicts, Undos/Redos, etc., which can be collectively referred to as data consistency problems. It is a research problem, because the processing results of concurrent conflicts need to ensure the consistency of the final data, which requires a lot of research , Demonstration.
The second category:
engineering problems, the focus is on the realization of a specific implementation plan based on the solution of “data consistency”. In addition to the functional points of specific implementation development mentioned above, performance issues and data transmission efficiency issues must also be considered. This area actually contains a lot of work, and is the key to whether theoretical research can really be implemented in production practice.
The solution to the first type of problem is the data consistency algorithm. There are two main research directions: OT algorithm and CRDTs.
Below we introduce these two algorithms.
Data consistency algorithm
I will not introduce the implementation details of the algorithm too much here, but only provide its ideas for handling conflicts, and look at the current processing ideas from the problem itself. As for the specific algorithm implementation, you can practice it privately if you are interested.
OT
The full name of OT is Operational Transformation. Its core idea is operation transformation, which solves various problems in collaborative editing by transforming data modification operations.
History
OT is the earliest (1989) proposed collaborative conflict processing algorithm
Applied to Google docs in 2006
Applied to Office 365 in 2011
So far OT is still the most important technology choice for collaborative editing (although PingCode Wiki did not choose OT, it does not affect its status), Google docs and Office 365 adopt OT solutions, and some document products have appeared in China in recent years , Including Shimo, Dingding, Tencent Document, Yuque, etc., their collaborative editing technology is also OT.
Main idea
Just like its name, its core idea is to convert the concurrent operations generated in the user’s collaborative editing, correct the concurrent conflicts and dirty paths generated by the transformation, and then reapply the corrected operations to the document. Ensure the correctness of the operation and the consistency of the final data.
Schematic diagram
We can use the diamon diagram to represent the core principles of OT
The left picture explains:
a represents the operation of the user on the left
b represents the operation of the user on the right
The intersection of the two indicates that the document is based on the same initial state
The state on the left: After the users on both sides apply operations a and b, the contents of the documents on both sides have changed at this time, and they are inconsistent;
Operation transformation: In order for the documents on both sides to reach a consistent state, we need to perform the operation transformation on a and b transfrom(a, b) => (a’, b’) to obtain two derivative operations as a’ and b’.
The result of the application operation transformation on the right: the derivative operation of the a operation of the user on the left a’ is applied on the user side on the right, and b’ is applied on the user side on the left, and the final document content is consistent.
The description here is only the most basic OT model. Each client has only one operation (1:1). In fact, there are cases where each client corresponds to multiple operations (M:N), as well as OT control algorithms, etc. Wait. And in the real implementation of OT, it is possible that each operation transformation will only get one derivative operation (operation transformation defined by ottypes), which is somewhat different from the previous transforms, but these are not the key points in this article. If you are interested, you can continue to study in depth. What is described here is only the most basic idea of the OT algorithm.
Solve the dirty paths problem with OT
As shown in the figure above, OT adds a layer of operation transformation logic in the process of operation synchronization to correct dirty paths generated by concurrent operations. When the left side synchronizes the right side operation, the index is converted from 4 to 5.
Operational transformation logic analysis:
For the user on the left: Because the local operation “Insert Access at Index=2” has been performed before the collaborative operation “Insert Testhub at Index=4” arrives, and the index of the local operation Index=2 is smaller than the index of the collaborative operation Index=4, Therefore, the index path of the collaborative operation should add the length of the newly added node locally, which is 1, and the index changes from 4 to 5.
For users on the right: Because the index path of the collaborative operation is smaller than the index path of the local operation, the local operation does not affect the collaborative operation, so there is no need to do any transformation, just apply the source operation directly.
Solve the problem of concurrency conflict with OT
It can be seen that solving the “concurrency conflict” based on OT also uses operation transformation logic, but this operation transformation does not convert the dirty path, but coordinates the conflicting attribute modification. The processing result of the above figure assumes that the operation on the right reaches the server after the operation. Yes, the final result converges to the right display.
From the analysis of the above two scenarios, it can be seen that this operation transformation process is not too complicated. Although there are more situations to be considered in the real scene than this, it is also a layer of logic transformation. There is also a real scene that requires cross-operation transformations for each operation type. For example, Delta supports three operations, then it may support 3*3 operation transformations, and Slate supports 9 atomic operations, which may need to achieve 9*9 This kind of operation transformation, the complexity is probably like this.
OT solves the undos/redos problem
As mentioned earlier, the essence of the undos/redos problem is the “dirty path” + “concurrency conflict” problem, so the solution of OT is that when the editor receives the cooperative operation, it needs to perform operation transformation on all operations in the Undo/Redo stack. The final operation performed during undo or redo is the transformed operation, and the specific logic will not be described in detail.
Algorithm description
It can be seen that OT is to transform the data operation of the editor, so the realization of the OT algorithm depends on the design of the editor’s data model. Different data models need to implement different operation transformation algorithms.
The OT algorithm probably ends here, let’s take a look at how CRDTs handles data consistency issues.
CRDTs
CRDTs (Conflict-free Replicated Data Type) is the “Conflict-free Replicated Data Types”. It is mainly used in distributed systems to ensure the data consistency of distributed applications. Document collaborative editing can be understood as a type of distributed application. Its essence is the data structure, and the final consistency of concurrent operation data is ensured through the design of the data structure.
CRDTs was formally proposed in 2011.
The CRDT-based collaborative editing framework Yjs was open sourced in 2015. Yjs is specifically designed for building collaborative applications on the web.
Main idea
Most CRDTs assign a unique identifier to each character created in the document.
To ensure that the document always converges, the CRDT model retains metadata even when characters are deleted.
CRDT was originally proposed to solve the final data consistency of the distributed system. It supports the direct synchronization of data modification between each host replica, and the synchronization sequence of data modification and the number of synchronizations do not affect the final result. As long as the modification operation is consistent, the data The final state of CRDT is consistent, that is, CRDT data meets the commutativity and idempotence that everyone often says.
How CRDT handles conflicts
The following figure describes the algorithm model of conflict handling in Yjs, which is a point-to-point conflict handling model.
The basic description of the above figure
- The bottom “AB” represents the initial state
- Each line above represents an insert operation
- Each operation has a unique identifier. For example, 0,0 in the C0,0 operation is an identifier, the first 0 represents the user number, and the second 0 represents the sequence of operations
For example, the following timestamp means that user 0 inserts “C” between “A” and “B”
C0,0The same user user 0 inserts “D” between “B” and “C”, you can use the following operation
D0,1At this time, another user expects to insert “E” between “A” and “B”, but this operation is a concurrent operation with the previous operation of inserting “C” (C0, 0). At this time, the unique identifier of the user should be different from the previous one, but the clock should be similar to the previous insert operation:
E1,0Due to concurrency conflicts, Yjs performs the same conflict resolution as OT and compares the user identifiers inserted by each. Since the user identifier 1 is greater than 0, the final result of the document is:
ACDEBThe above is the introduction of Yjs’s algorithm for handling concurrency conflicts. In fact, it is not difficult to understand. First of all, its insertion operation is based on the relative position of existing characters. The use in OT is equivalent to the absolute position based on the index, and then the conflict processing. It compares the user identifier, the smaller one is applied first, and the larger one is applied later.
The above uses Yjs as an example to introduce CRDT’s conflict handling model. Let’s take a look at how CRDT solves the previous problems.
CRDT solves the dirty path problem
Describe the array just now in a way similar to CRDT:
You can see that the list on the right uses a unique Id to replace the index of the original array, and then the operation of describing content modification also needs to be adjusted
Operation on the left:
Insert Access at Index=2 -> Insert Access after 111
Operation on the right:
Insert Testhub at Index=4 -> Insert Testhub after 333
After the synchronization operation, the final data structure on the left and right should be the same:
Because this is just a simulation of CRDT to explain the idea of CRDT, the real CRDT usually uses a doubly linked list. Here, in order to make it easier to understand, the array is still used, but a unique identifier is added to each paragraph node data in the array.
CRDT resolve concurrency conflicts
Here is an example of setting the alignment of pictures. First, let’s take a look at how CRDT describes object properties and property modifications:
On the left is the image data model, and on the right is the data structure corresponding to the simulated CRDT. Each field in the image object uses a structure object to describe content and content modification. Here, the align field is used as a representative to see its expression:
Operation ①:
The top blue part represents the initial value of align is center, (140, 20) is the identification of this initial data structure, which is also generated based on an operation of the user.
At this time, a user performed the operation ①, changed align to left, and created a new structure object, which is represented by the orange part in the figure. After the operation is completed, the align field points to the newly generated structure object, the identifier is (141,0), because (141,0) this structure object is based on the modification of (140,20), so its left points to (140 , 20) This structural object.
There are some confusion in this example, that is, the data structure of the linked list itself has two pointers, left and right (on the left and right sides of the structure object), and the middle part is actually the content, but my content stores the align attribute of the image, and its value It may be left, center, and right, which may cause confusion with the linked list in the left and right pointers. Under the mark, the second block in the structure object describes the attribute content.
Operation ②:
At this time, another user performed an operation ② based on the structure object (141,0) that was just generated, and changed align to right, resulting in a new structure object, which is represented by the orange-red part in the figure. The lower part of the picture is the final data structure after these two operations. It is an expression of a doubly linked list (this expression is very close to the real data structure of Yjs). It can not only describe the final data state (right), but also The order of data modification can be expressed: center -> left -> right.
This example actually describes sequential operations. The state based on each operation is the latest state, and the operations performed by two users have a definite order.
Let’s take a look at the data structure generated when two users execute attribute modification concurrently:
The biggest difference from the previous one is that the execution operation ② and the execution operation ① are based on the same state, and they are all modified based on align = “center”. This situation expresses concurrent operation. The next step is the logic of concurrent processing. Apply the conflict processing algorithm introduced earlier. At this time, the corresponding user ID 141 of operation ① is smaller than the user ID 142 of operation ②, so operation ① is applied first, followed by operation ②, so the final picture should be It is displayed on the right.
CRDT solves the undso/redos problem
CRDT can be understood as there is no “dirty path” problem, and the problem of concurrency conflicts can also be resolved based on the CRDT identifier (time stamp), so in the CRDT-based solution, the implementation of undos/redos should be relatively simple, just based on Adding or deleting CRDT data structures to implement the undos/redos stack can effectively solve the problem.
If an operation to generate a structure object is performed, it may be marked for deletion when it is undone.
If an operation to delete a structure object is performed, the execution of the undo operation may correspond to the re-execution of the insertion operation of the structure object.
CRDT algorithm description
Different from OT, CRDT is a new solution. It does not rely on the editor data model. Any data model can use a unified CRDT data structure to handle conflicts. It is also because of the characteristics of CRDT that it can not rely on centralized Server, and its stability is very high. This is different from OT. OT can be understood as ensuring data consistency through algorithm control. CRDT ensures data consistency through data structure design. Its processing in a complex network environment is more reliable. The price of CRDT is to save more metadata, which will bring additional memory consumption, but this is optimizable. It turns out that this price is completely acceptable in collaborative editing scenarios.
Yjs optimization
In fact, the CRDT-based collaborative editing program has always been questioned, and the voice of doubt has been still there, and Yjs is also affected by it. Although Yjs based on CRDT is so powerful, everyone still talks about CRDT’s memory overhead and performance overhead. According to my current understanding: memory overhead and performance issues are no longer a problem for Yjs, so here is an introduction to Yjs The optimization of this part of the content is based on the official introduction to Yjs optimization. There are a lot of benchmark tests to verify each point of performance problems and memory usage problems. Only some optimization methods are introduced here.
1. Structural representation optimization
When the user enters the content “ABC” from left to right, it will perform the following operations: insert(0, “A”) • insert(1, “B”) • insert(2, “C”). The linked list of YATA CRDT modeling text content will look like this:
CRDT model with content “ABC” inserted (assuming the user has a unique client identifier “1”)
All CRDTs assign a unique ID and additional metadata to each character, which consumes memory for large documents. We cannot delete metadata because it is necessary to resolve conflicts.
Yjs also uniquely identifies each character and assigns metadata, effectively representing this information. Larger document insertions are represented as a single Item object, using character offsets to uniquely identify each character individually.
Then this part can be optimized, the following Item can also uniquely identify the character “A” as {client:1,clock:0}, the character “B” as {client:1,clock:1}, and so on. …..
Item {id: { client: 1, clock: 0 },content: 'ABC',length: 3,...}
If the user copies/pastes a large amount of content into the document, the inserted content is represented by a single Item. In addition, single-character insertions written from left to right can be combined into a single Item. The important thing is that we can split and merge items without losing any metadata.
This is the optimization of Yjs for data representation. In this way, the number of structure objects in the Yjs data structure can be effectively reduced, thereby effectively reducing the memory usage.
However, the most important disadvantage of this method is that it becomes more complicated to deal with individual characters (it doesn’t matter, because this is what the Yjs framework does). When another user wants to insert a character between “B” and “C”, the “BC” part of the operation needs to be split into two separate operations. We cannot regroup these operations, because in CRDT we can never delete characters or delete them from the document tree.
2. Deletion optimization
The only way we can express that a character needs to be deleted is to mark it as deleted. Even so, this part can still be optimized. Take Slate’s paragraph structure as an example. When you mark a paragraph for deletion, you can also mark all text structures under the paragraph for deletion.
For example, if a paragraph contains the text “ABC”, when the marked paragraph is deleted:
(Paragraph) D
It is equivalent to marking all the following text nodes (characters) as deleted:
AD BD CDAt this time, we can completely delete all the structure corresponding to the character node from the memory, because the character node is the child node of the deleted paragraph.
Based on this method, the memory footprint of Yjs can also be effectively reduced.
3. operation definition
This piece is actually to optimize the creation of Yjs structural objects from the perspective of V8. The overall idea is to allow the process of Yjs to create objects to be optimized by the browser, whether it is memory usage or object creation speed.
4. query optimization
Everyone should know that the biggest problem of using a doubly linked list is query performance, because for every operation you need to traverse the entire linked list to query a certain structure object, when the Yjs structure object data is very large, every operation performed may be lost due to this. For a certain period of time, Yjs also has optimization measures for this. At present, what I see from the source code is that Yjs will cache the structure objects frequently operated by users (in fact, the cache location), and prioritize them in the cache during the search process. Matching can effectively improve the data query speed if the cache hits.
5. coding optimization
Yjs will perform unified binary encoding on the structural objects transmitted in the network and stored in the database, and of course it will also provide response decoding operations. Binary encoding can effectively provide data transmission efficiency.
OT vs CRDT
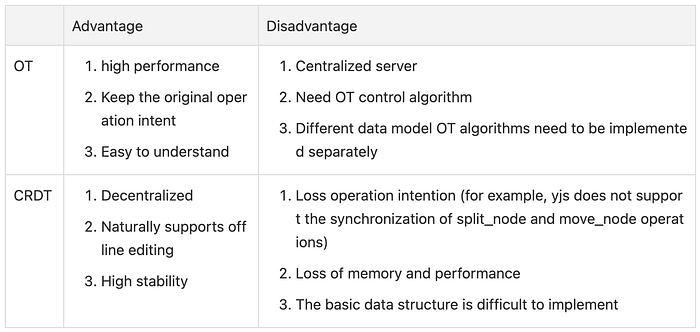
This is the part of the OT and CRDT algorithm. The following describes the project implementation plan based on the OT and CRDT algorithm in actual development.
Open source solution
Two solutions are mainly introduced here, one is the ShareDB solution based on OT, and the other is the Yjs solution based on CRDT.
ShareDB solution
For OT, the community has always had a corresponding solution-sharedb, but it is a pity that there is no clear solution on how to combine slate and sharedb. I searched on Github and found that some people have studied it, but it is only for the older slate The version is not maintained much, but its implementation has given me some ideas. With the original understanding, I have the current solution: slate + ottype-slate + sharedb.
ShareDB
ShareDB is a set of solutions based on OT to achieve collaborative editing, providing collaborative message synchronization, cursor synchronization, data persistence, OT control algorithms, etc., and because the implementation of OT algorithms is linked to specific data structures, there is no set of universal Therefore, ShareDB itself does not include the implementation of the OT algorithm. It is responsible for the part of the collaborative editing project. Now the default OT algorithm uses ot-json0. The final architecture diagram of ShareDB is as follows
The light blue part below is the main module included in ShareDB. ShareDB will provide a WebScoket-based message service implementation and the corresponding front-end message service SDK, which can synchronize operations and cursors. ShareDB also includes the implementation of data persistence. The left most OTType is the part of the core operation conversion. Because the data models of different editors need to implement separate OT algorithms, ShareDB itself does not include the implementation of OTType, so ShareDB provides a standard access interface. Any data type as long as it is based on this The interface implements the corresponding operation transformation algorithm, then it can be connected to ShareDB through registration. The definition of this standard interface can refer to the implementation in ottypes.
The purple part above is the editor currently supported by ShareDB. The final task for the editor to connect to is to implement its own OTType based on the data model of the editor, and then the Delta data model of the Quill editor itself realizes the operation conversion. Logic, Quill is the easiest to access.
ottypes
As mentioned earlier, ottypes actually defines a standard OT interface. The type transformation implemented according to this standard can be used perfectly with ShareDB to complete the collaborative editing of data. The ottype mentioned in the previous scheme ottype-slate is actually an implementation of ottypes.
ottype-slate
Personally, I feel that the data model and data transformation defined in slate are very readable. Its expression and the tool functions provided are very clear and complete, and each atomic operation is reversible. I probably read what sharedb supports by default. Implementation of JSON-based operation transformation (ot-json0), ot-json’s expression for data modification is still very readable, so I feel that I can write an OTType implementation for the slate data model by myself, so there is ottype-slate.
ottype-slate currently only implements part of the operation transformation functions initially, and then combines slate-angular and sharedb to build a collaborative editing test demo. The remaining part of the operation transformation functions will be added later.
ShareDB solution flow chart
From the above point of view, if the user is performing collaborative editing based on the Slate editor, you can see that the operations generated by the user content modification may perform operation transformation before being passed to the ShareDB Server, depending on the document version on which the operation is based and the document of the server Whether the versions are consistent or not, you need to calculate the partial operations of the differences between the two versions, take the difference operations and the newly generated operations for operation conversion, and synchronize the modification of the content based on the results of the operation conversion. After this process, the final operation is passed. The message service is forwarded to other clients, and other clients are applying this operation to realize collaborative editing.
It can be seen from this process that the operation transformation may eventually be performed on the server side or on the client side. Because the operation conversion process requires the coordination of multi-client operation conversion through the OT control algorithm, this process must go through a centralized server, otherwise the process is difficult to control, so this solution based on the OT algorithm cannot achieve point-to-point communication.
Yjs solution
Yjs is an open source solution based on CRDT. It provides a relatively complete ecology. In 2020, the community also has an intermediate binding layer based on the Slate editor. Its architecture is as follows
y-websocket — Provides message communication during collaborative editing, including SDK for server-side implementation and front-end integration
y-protocols — defines the message communication protocol, including message service initialization, content update, authentication, perception system, etc.
y-redis — Persist data to Redis
y-indexeddb — Persist data to IndexedDB
In the upper layer, Yjs supports the access of most mainstream editors, because Yjs can also be understood as a set of independent data models, which are different from the data model of each editor itself, so each editor wants to access Yjs must implement an intermediate binding layer for the conversion between the editor data model and the Yjs data model. This conversion is two-way. The official currently provides an intermediate binding layer for editors such as Prosemirror, Quill, Ace, etc., based on the Slate editor The intermediate binding layer is provided by community developers.
Yjs flow chart
Describe the synchronization process of user operations from top to bottom. If the user above is modifying some data based on the Slate editor, the operations generated by it need to be converted to Yjs data modification through Yjs Bindings (using applySlate) Update the data structure of the local Yjs. When the data structure of Yjs is modified, it can synchronize the changes of the data structure to the collaborator through a network transmission protocol, and the collaborator can directly use this remote data to synchronize to the local Yjs data structure. , And then there is a subscription operation in Yjs Bindings, which is to subscribe to remote Yjs data modification, and then use the applyYjs method to convert the expression of Yjs data modification into Slate operations. Finally, Slate applies this operations to achieve content synchronization, and the problem of concurrency conflicts in the middle It is completely handed over to the Yjs data structure for processing, and the conversion to Slate will always be consistent with the Yjs processing result.
It can be seen from the flowchart that each client maintains a copy of the Yjs data structure. The content of this data structure copy is exactly the same as that of the Slate editor data, except that they have different responsibilities, and Slate data is available for editing. The Yjs data structure is used to handle conflicts and ensure data consistency. The data modification is finally synchronized through the Yjs data structure.
It is worth mentioning that the Yjs data structure itself supports point-to-point data synchronization, without the help of a centralized server.
PingCode Wiki Collaboration Solution
In 2021, the technology should change, and the collaborative editing program should not only be OT. Let’s talk about our considerations when selecting technology.
Our team officially started to do collaborative editing in Q3 this year. Our editor is based on the Slate framework. Although I did some research on collaborative editing before this, it was not a system. So we did it again at the beginning of Q3. According to the survey, the core question is whether to choose OT or CRDT. Here are some of the information we have at the time:
Abount OT
- The TinyMCE editor is based on the Slate model + OT to achieve collaborative editing, but theirs is not open source
- Collaborative editing solutions for products of large companies are all based on OT
- For OT, I only understood the idea at the time and didn’t know how to implement it. To be precise, I didn’t know what functional modules should be included in collaborative editing.
Abount CRDT
- The community has always had some doubts about CRDT
- CRDT has fewer application cases on document products
- Yjs ecosystem is relatively complete, based on the Slate editor, there are mature demos
- Translated some Yjs technical documents, and I have a good impression of Yjs
- Build a Yjs collaborative editing Demo based on our editor, which can run through
The screenshot of the Demo provided by slate-yjs, which was investigated at the time, is as follows
It can be said that the function of this demo is very complete, and the technology stack is basically in line with us.
Although there are some doubts about the CRDT community, the facts always need to be verified. Because of Yjs’s comprehensive demo and initial impression of it, we decided to give it a try according to Yjs’s plan.
This is basically the process of our selection, because the subsequent process is very smooth. First, we quickly built the first version of collaborative editing on the test environment based on the Yjs ecosystem. We are re-implementing a message service module. Plus authentication, and then based on the step-by-step investigation and repair of some detailed problems of collaborative editing, including the control of message service connection, undos/redos problems, pop-up processing, etc., in short, there is no big problem, and the performance is basic There is no loss, and the loading of large documents (about 50,000 to 60,000 words) can basically be processed by Yjs in milliseconds.
Now let’s look at the choice of Yjs plan again. I think the choice of our plan is very correct. The team is very efficient in collaborative editing. In this process, everyone is very relaxed. You can learn a lot on Yjs. The following is I summarized some of the advantages of Yjs in function and design:
Functionally:
- Provide a complete awareness system, users synchronize online status, cursor position
- Support offline editing
- Network agnostic, can handle network jitter, network delay and other issues
- Provide undos/redos management
- Version history
- …
In design:
- Module responsibilities are clearly divided, especially the extraction of an independent protocol library y-protocols, which makes complex message synchronization very clear
- Network protocol/data persistence Realize loose coupling, network protocol supports access to y-websocket, y-webrtc, persistence y-redis, community provides y-mongodb
- Can be quickly integrated with any editor
It can be said that what Yjs means to us now is just what Slate means to us two years ago. It is an important material for us to understand and learn collaborative editing at this stage. What is included in realizing collaborative editing? What are the problems with realizing collaborative editing? How does Yjs solve these problems, what are the shortcomings of Yjs, how does it optimize performance, etc., just like a teacher to help you complete your work, and then make you progress in the process❤️.
Talk about the evolution of technology
The OT algorithm was proposed in 1989, which represented the beginning of collaborative editing technology. However, the architecture concept of the editor at that time was far from reaching the current level. Its concept must be very advanced during that period. The abstraction and development of the current editor data model is also It is related to OT.
In 2006, Google really brought OT to the document product. This process went through more than ten years, and then in 2011, Microsoft implemented collaborative editing based on OT. It took about 5 years in the meantime. I think this time span It must have something to do with the background of the editor technology at that time. In this period, the collaborative editing technology was actually only developed and applied in these top technology companies.
The proposed CRDT algorithm in 2011 represented the emergence of a new collaborative editing solution.
The Quill editor was open sourced in 2012. Its data model Delta is designed based on the OT algorithm. I personally feel that the open source of the Quill editor is an important milestone for collaborative editing and the development of OT. In the past, collaborative editing may have been studied by a few large companies. After the Quill editor, collaborative editing has gradually been applied to more small and medium-sized company products. For example, the core technology of Shimo documents in China, including collaborative editing, is based on Quill and Delta.
ShareDB was open sourced in 2013, which represents the landing of a complete solution based on OT.
The open source of Yjs in 2015 represents the official development of a collaborative solution based on CRDT. In 2019, the Slate framework is completely refactored based on TypeScript, and its data model has been further optimized. It is now extremely concise and elegant. I think this also represents a change.
In 2020, slate-yjs is open source. It is a combination of Yjs and Slate. With this combination, there is actually a complete collaboration solution based on Slate.
In 2021, I think it is reasonable for us to choose Yjs at this time. The choice of technology in different periods must be different.
I want to extend the point here is that the OT algorithm is actually a solution implemented on the existing editor architecture, and its implementation is also well understood. In fact, the other way round is that the current data consistency problems encountered by collaborative editing are also part of Due to existing data operation models, such as index-based positioning in data modification operations, this has caused the dirty path problem. In short, OT can be understood as a solution to fill existing defects. Then CRDT is actually a new solution and a technological innovation. It has many excellent features, such as supporting point-to-point data synchronization, and its conflict handling is actually more stable, although CRDT’s data structure It is more complicated, but this complexity can be well encapsulated by the framework layer.
Ending
This article is actually the theme content prepared for the “PingCode Developer 2021” held by our company this year, and then I actually want to organize the content of collaborative editing. I took this opportunity to do it together, mainly Explained my understanding of this technology, including what collaborative editing is, some of the problems or challenges encountered by collaborative editing, and how the mainstream collaborative editing conflict processing algorithm works, and then to the following conflict processing algorithm based Open source solutions and so on. Most of the technologies mentioned here are actually open source. In fact, I really admire the contributors of these open source works, and I am also urging myself to make more open source output.
Open source address:
https://github.com/quilljs/quill
https://github.com/pubuzhixing8/ottype-slate
https://github.com/qqwee/slate-ottype
https://github.com/share/sharedb
Reference article
SharedPen 之 Operational Transformation
This Is How to Build a Collaborative Text Editor Using Rails
Yjs deep dive: How Yjs makes real-time collaboration easier and more efficient
https://blog.kevinjahns.de/are-crdts-suitable-for-shared-editing/
Awesome-colaboraiton
